本稿は前稿「DPC評価分科会のデータをダウンロードするのが大変なのでPythonを使ってウェブスクレイピングしてみた。BeautifulSoup」の補足記事です。
2019年(令和元年)のデータ「令和元年度DPC導入の影響評価に係る調査「退院患者調査」の結果報告について」は上手くいったのに、他の年度について上手くいかなかった方への補足です。
Contents
【補足記事】DPC評価分科会のデータをダウンロードするのが大変なのでPythonを使ってウェブスクレイピングしてみた。BeautifulSoup
そのまま他の年度に適応しても上手くいかない時がある
前回紹介した記事通りに、令和元年データのスクレイピングを実施してうまく行ったのに、他のもっと前の年度、例えば平成29年度分をそのまま試してみると失敗してしまいます。
上手くいかない原因
上手くいかない原因は何でしょうか?こういうときは、エラーメッセージを確認することと、一気に完成したプログラムを走らせるのではなく、区切り区切りでどのようなデータが扱われているか確認をしていく事が重要です。
エラーメッセージを確認
実際にプログラムを走らせてみると下のようなエラーメッセージが出ます。

リストの長さがおかしい様です。
プログラムを区切って確認
逐次区切ってデータを見ていってみます。
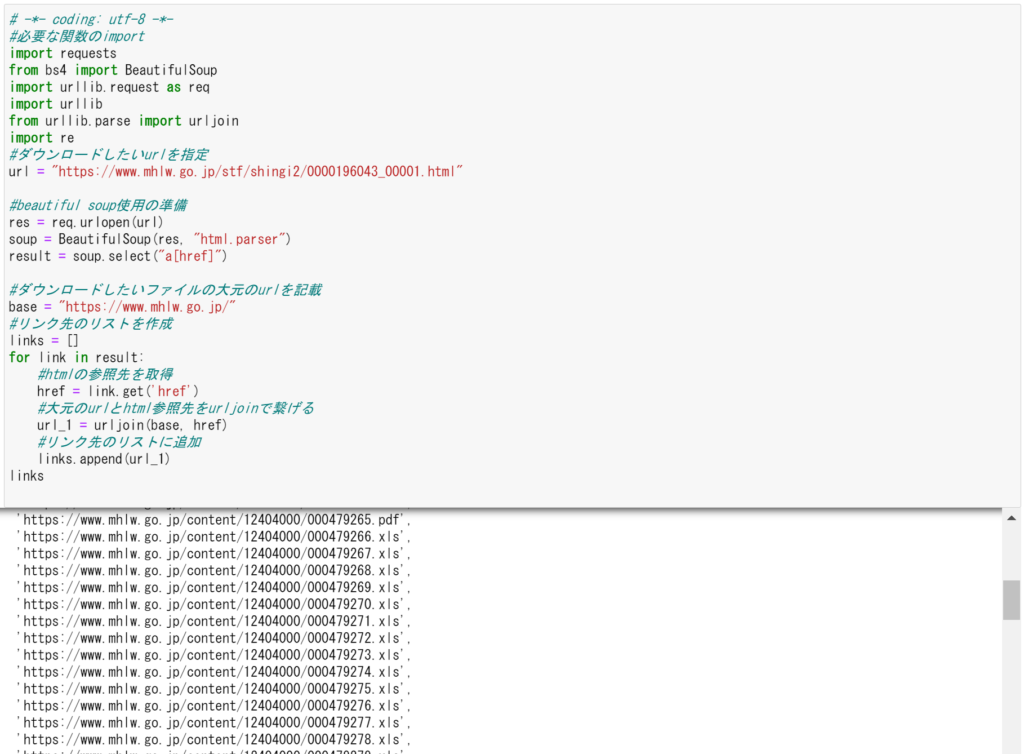
作成したlinksのリストの内容をよく見ると、令和元年データではエクセルの拡張子はxlsxであったものが、平成29年の物ではxlsになっている様です。
プログラム中に記載している拡張子xlsxをxlsに変更してプログラムを走らせてみると、今後はエラー無く走らせる事が出来ました。
まとめ
今回、令和元年度のデータの引用元のurlを平成29年のurlに変え2017年表記にしただけではエラーになってしまう原因は、エクセルの拡張子の記載の違いから上手くリストが出来なかったことによるものでした。
エラーになってしまった場合でもエラーメッセージを確認し、プログラムを区切って確認していくと、正解に近づくことができます。


